從CPU運行到函數調用 計算機程序執行的微觀探秘
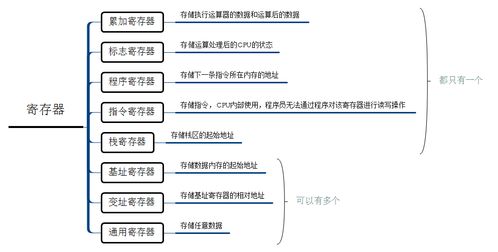
在計算機科學的世界里,程序的執行并非魔法,而是一系列精密、有序的步驟。理解從中央處理器(CPU)的常規運行到函數調用的具體過程,是深入編程和系統設計的關鍵。本文將以通俗的方式,解析這一微觀旅程。
一、 CPU的日常:取指、解碼、執行
CPU是計算機的“大腦”,其核心工作循環可以概括為三個步驟:
- 取指(Fetch):CPU從內存中,按照程序計數器(PC)指向的地址,讀取下一條要執行的指令。
- 解碼(Decode):控制單元對取到的指令進行解析,識別出需要執行什么操作(如加法、數據移動)以及操作數在哪里。
- 執行(Execute):算術邏輯單元(ALU)或其他相關部件根據解碼結果,實際執行該指令,比如完成一次計算或將數據寫入寄存器。
執行完畢后,程序計數器會自動更新,指向下一條指令的地址,循環就此周而復始,推動程序順序執行。
二、 當遇到函數調用:流程的“岔路口”
當CPU順序執行的指令是一條“函數調用”(例如C語言中的 call func 或高級語言中的 func())時,這個平靜的循環將被打破,流程需要轉向另一個獨立的代碼塊。這個過程遠比跳轉指令復雜,因為它涉及“如何回來”以及“如何保持現場”。
一個完整的函數調用過程,可以分解為以下幾個關鍵階段:
1. 調用前:參數傳遞與返回地址壓棧
在跳轉到函數代碼之前,調用者需要做好準備:
- 參數傳遞:按照調用約定(如C語言的從右向左壓棧),將函數所需的參數值放入指定的寄存器或壓入棧(Stack) 這一內存區域。
- 保存返回地址:將函數調用指令之后的那條指令的地址(即“返回地址”)壓入棧中。這是函數執行完畢后,CPU能知道回到哪里的關鍵。
2. 跳轉與現場保護
- CPU更新程序計數器(PC),跳轉到被調用函數的起始地址,開始執行函數體的指令。
- 函數開頭通常會執行序言(Prologue),將當前函數需要使用的某些寄存器(稱為“調用者保存寄存器”)的值壓棧保存。這保護了調用者的運行現場,確保函數返回后調用者能無縫銜接。
3. 函數體的執行
- 此時,CPU就像執行普通代碼一樣,在函數體內進行取指、解碼、執行的循環。函數可以通過棧指針(SP)的相對偏移來訪問傳入的參數和自身的局部變量(這些局部變量也在棧上分配空間)。
4. 返回前:清理與恢復現場
- 函數執行到 return 語句時,會將返回值存入約定的寄存器(如EAX/RAX)。
- 接著執行尾聲(Epilogue),恢復之前保存的寄存器值,并調整棧指針,釋放本函數用于局部變量和保存現場的空間。
5. 返回與后續執行
- 執行一條返回指令(如 ret)。該指令會從棧頂彈出之前保存的返回地址,并讓CPU跳轉到該地址繼續執行。
- 調用者根據調用約定,可能需要進一步調整棧指針以清理傳入參數的空間,然后從返回值寄存器中獲取結果,繼續向下執行。
三、 核心支撐:棧(Stack)的關鍵角色
縱觀整個過程,棧這一“后進先出”的內存數據結構起到了核心的“記事本”和“工作臺”作用。它按順序記錄了:返回地址、調用者幀指針、參數、局部變量等。每一次函數調用,都在棧上分配一個獨立的區域,稱為“棧幀”。棧指針(SP)和幀指針(FP)寄存器共同管理著這些棧幀的邊界,使得嵌套函數調用和返回能井然有序地進行。
###
從CPU的基礎運行周期到復雜的函數調用,計算機通過硬件(PC、SP寄存器)與軟件(調用約定、棧管理)的精密配合,實現了代碼的模塊化執行與流程控制。理解這個過程,不僅能幫助程序員寫出更高效、bug更少的代碼(例如理解棧溢出),也是學習操作系統、編譯原理等更深層知識的堅實基石。這正如一位名為“littlehero 121”的CSDN博主可能分享的那樣:窺探這微觀世界的運行機制,是每個編程愛好者成長為真正“高手”的必經之路。
如若轉載,請注明出處:http://www.02170.cn/product/49.html
更新時間:2026-01-06 09:11:42